Building a generic data publisher pipeline using AWS
Introduction
Data is turning out to be the most important asset in the modern tech era. Businesses often feel a need to publish data at scale for various aspects such as analysis, recovery and reporting. This article elaborates a scalable and extensible solution for publishing data directly from the application to a data warehouse using AWS.
Motivation
AWS resources can be pretty expensive if not used optimally, especially when dealing with data at scale. The idea is to design a cost-effective and re-usable solution by putting together a set of minimal AWS resources required to achieve this.
Design
In this article, I will discuss 2 approaches. The second one being an enhancement over the first. The former is an existing and most commonly used architecture and the latter being an optimal version of it.
Approach 1: DataPublisherLibrary -> SNS -> SQS -> Lambda -> Firehose ->Redshift
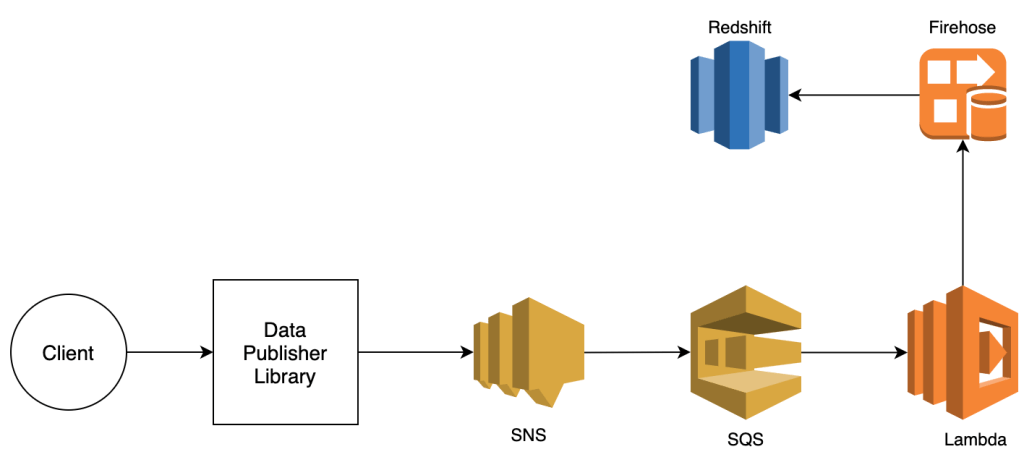
Let’s look into these components one by one.
DataPublisherLibrary: When building a solution meant to be reused across applications, It is best to write all the boilerplate code in a library, expose a method which can publish to SNS and let your clients consume it. The client only has the responsibility to call this method with data being passed as payload.
SimpleNotificationService: The whole point of introducing SNS into the flow is the fact that SNS can have multiple subscribers which makes the design more pluggable. In future, The system can be extended to undertake other responsibilities by splitting the flow into multiple pipelines.
SimpleQueueService: There are 2 reasons good enough to couple SQS with SNS w.r.t this use-case:
- Data flow control: Consider the case where Lambda was directly attached with the SNS, Each event published to SNS will trigger this lambda which increases the risk of throttling because lambda has a concurrency limit(which is 1000 parallel invocations). Using SQS, Lambda can poll 10 records(max) thereby making a batch call to firehose to append records which reduces the number of invocations by a factor of 10. Adding to the benefits, This will also reduce the overall cost incurred by the system(provided number of lambda invocations have already exceeded 1 million).
- Fail-safe mechanism: SQS can be attached to a lambda to act as a Dead Letter Queue(DLQ) for retrying failed messages.
Lambda: Lambda is a highly scalable, serverless code execution platform which is triggered based on the events received by other AWS services. In this case, Lambda is performing a batch call to firehose for every 10 records sent to the queue.
Introducing Lambda in the pipeline also provides great flexibility for data manipulation and filtering. It gives you complete control over data in-transit.
Kinesis Firehose: Firehose is where all the incoming data gets aggregated before being dumped into redshift. Redshift can incur massive costs originating mainly from I/O operations if not configured properly, thats why it is extremely important to minimise I/O operations to redshift. Using firehose, data can be accumulated at scale with literally no I/O cost. The aggregated data is then transferred to redshift minimising I/O thereby rendering the design extremely cost effective.
Redshift: Finally redshift is a data warehouse for managing/querying petabytes of data. Although redshift is widely used, There is a cheaper alternative “Amazon Athena” which is also a petabyte scale serverless data warehouse. Depending upon your use-case you can choose between these two.
Approach 2: DataPublisherLibrary -> EventBridge -> Firehose -> Redshift.
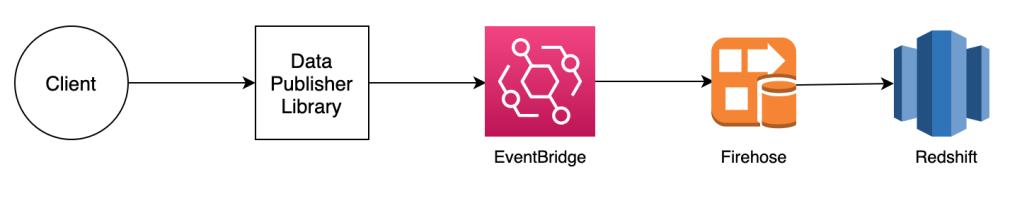
Approach 1 proved to be the most optimal design for publishing data at scale until amazon introduced a service called as “AWS EventBridge”.
So, What is all this hype about EventBridge? Why is it so much better? Lets dive-deep into this….
AmazonEventBridge: EventBridge just like SNS works on a Pub/Sub model, What makes it so much better is its direct interaction with a lot of AWS Services(lot more than SNS) and strong support for incoming data manipulation and filtering. Having this said, SQS and Lambda are completely out of the picture so we don’t have to worry about data flow control and buffering because event-bridge directly passes the incoming event to Firehose. On top of that all the manipulation logic can be handled in eventbridge instead of coupling the design with lambda.
Advantages over the former approach:
- Cost: When dealing with massive amount of data, The latter approach proves to be extremely cost effective.
- Easily maintainable: The latter uses significantly less number of resources which makes management easier and enhances maintainability.
- Concurrency: No need to look out for throttling cases as EventBridge is a highly scalable server-less resource.
- More pluggable: EventBridge offers a huge number of AWS resources as targets which obviously makes the architecture more pluggable.
The rest of the components will perform similar functionalities, The DataPublisherLibrary will call EventBridge instead of SNS.
